摘要:来源:本文内容来自tom’shardware,谢谢。当Tachyum在Hot Chips 18上推出其Prodigy通用处理器的概念时,它的芯片设计用于使用动态二进制翻译器运行任何代码,引起了轰动。它在执行本机代码和翻译代码时都表现出高性能...
来源:本文内容来自tom’shardware,谢谢。
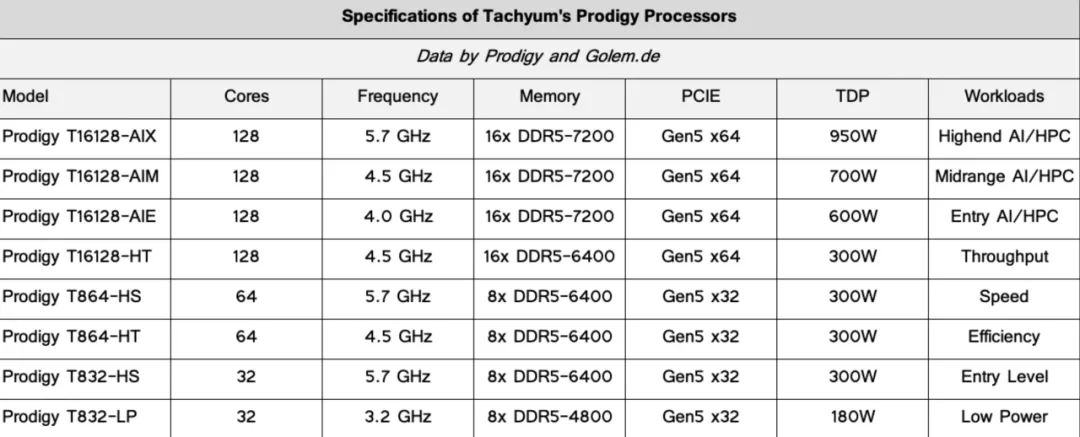
当Tachyum在Hot Chips 18上推出其Prodigy通用处理器的概念时,它的芯片设计用于使用动态二进制翻译器运行任何代码,引起了轰动。它在执行本机代码和翻译代码时都表现出高性能。该公司花了一段时间来设计实际的硬件,接受评估套件的预订(在新标签中打开); 该公司还披露了其 Prodigy 的确切规格。它们看起来确实令人印象深刻,但每个芯片 950W 的热设计功率也令人恐惧。
128个专有内核,5.7GHz、16个 DDR 5内存
每个 Tachyum Prodigy 处理器具有多达 128 个专有内核,与 16 个 DDR5 内存通道(用于 1,024 位接口)配合,支持高达 7200 MT/s 的数据传输率(因此提供高达 921.6 GBps 的带宽)以及 64 个 PCIe 5.0 车道。此外,该芯片总共支持高达 8TB 的 DDR5 内存,这与我们将在其他制造商即将推出的服务器 CPU 中看到的一致。至于时钟频率,Tachyum 的 Prodigy 设计运行频率高达 5.7 GHz,是台积电性能优化的 N5P 工艺技术的产物。
(图片来源:Golem.de)
在性能方面,Tachyum 期待其旗舰 Prodigy T16128-AIX 处理器能为HPC 提供高达 90 FP64 TFLOPS 以及为推理和训练提供高达12 个“AI PetaFLOPS”,据推测当运行本机代码时消耗高达 950W(并使用液体冷却)。同时,Tachyum 的 Prodigy 处理器可以在 2 路和 4 路配置下工作。具体来说,AMD 的 Instinct MI250X 在大约 560W 的 HPC 中具有 96 FP64 TFLOPS 的峰值吞吐量。相比之下,Nvidia 的H100 SXM5 可以在 700W 时为AI提供高达20 INT8/FP8 PetaOPS/PetaFLOPS(稀疏性时高达 40 PetaOPS/PetaFLOPS)。然而,这两种计算gpu都不能用于通用的工作负载。这正是有趣的地方。
新CPU诞生
Tachyum 的 Prodigy 是一款通用同质处理器,最多可容纳 128 个专有的 64 位 VLIW 内核,每个内核具有两个 1024 位矢量单元和每个内核一个 4096 位矩阵单元。此外,每个内核都有一个 64KB 指令缓存、一个 64KB 数据缓存、1MB L2 缓存,并且可以利用其他内核未使用的 L2 缓存作为受害 L3 缓存。

(图片来源:Tachyum)
Tachyum 的首席执行官兼联合创始人 Radoslav Danilak 与 Golem.de交谈时表示,Tachyum 的 VLIW 内核是有序内核,但当编译器制造商进行适当优化时,它们可以支持 4 路无序问题。(在新标签中打开). 他还再次强调,Prodigy 指令集架构可以通过使用所谓的毒位的软件实现非常高的指令级并行性。
据该公司称,这些内核运行为 Prodigy(VLIW 架构有望大放异彩)以及 x86、Arm 和 RISC-V 二进制文件编写并明确优化的本机代码,使用软件仿真并且不会降低性能。从历史上看,所有让 VLIW 处理器执行 x86 代码的尝试都失败了(例如,Transmeta 的 Crusoe、Intel 的 Itanium),主要是因为特定的 CPU 架构和仿真效率低下。Tachyum 的负责人承认,Qemu 二进制翻译将性能降低了 30% 到 40%(没有透露任何基线),但希望现实世界的性能仍然足够高以具有竞争力。同时,一些程序已经原生支持。
“我们本机支持 GCC 和 Linux,而且 FreeBSD 现在也可以在 [on Prodigy] 上运行,”Danilak 说。“Apache、MongoDB 或 Python 已经原生运行,Pytorch 和 Tensorflow 框架也可用。”
Tachyum 强调,Prodigy 不是加速器,而是真正的 CPU,将与 AMD、Intel 和其他公司竞争。为确保处理器能够在通用和 AI 工作负载中提供具有竞争力的性能,自 2018 年首次推出以来,该公司对其设计实施进行了大量更改。
“我们是 CPU 替代品,而不是 AI 加速器公司,我们的目标是云/超大规模和电信公司,”Danilak 说。“随着时间的推移,我们计划赢得一些超级计算机客户,因此我们将向量/MAC 单元的宽度从 512 位增加到 1,024 位 [这也为人工智能的 4,096 位矩阵运算带来了必要的数据路径]。”
事实上,Tachyum 的 Prodigy 承诺的一个特别优势是它能够执行不同类型的代码。假设它可以在执行通用工作负载(实例)的同时以不错的功率提供不错的性能,它可能会为 AWS、Microsoft Azure 等提供一些额外的灵活性,因为它们将能够将相同的机器用于 AI、HPC、和通用实例(如果需要)。当然,它需要来自不同方的一些实际软件工作,但这可能会奏效,至少在理论上是这样。
到2023年才能量产
应该指出的是,Tachyum 仍然没有任何 Prodigy 芯片。因此,所有的性能预测都是模拟的产物,而该公司现在唯一拥有的是其处理器的 FPGA 原型。

(图片来源:Tachyum)
与此同时,该公司最近开始接受Tachyum 的 Prodigy 评估平台的预订,该平台将用于一些 Prodigy 芯片。公司必须在 2022 年 7 月 31 日之前下订单,实际硬件的交付时间约为“收到订单后的六到九个月”。
如果一切按计划进行,Tachyum 预计将在 8 月中旬流片出第一个 Prodigy 芯片(可能小于 500 mm^2)。在那之后,该公司预计将在 12 月左右获得其芯片的第一批样品,如果芯片工作正常,该公司计划开始提供样品(即发送评估套件)。通常,芯片从晶圆厂返回后大约需要一年时间。尽管如此,Tachyum 仍希望其首款处理器能够按计划工作,并能够在 2023 年上半年开始实际量产。
在未来,Danilak 设想使用台积电的 N3 节点之一制造的 Prodigy 2 处理器将在相同的功率下提供两倍的性能以及 PCIe Gen6 支持。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3068内容,欢迎关注。
晶圆|集成电路|设备|汽车芯片|存储|台积电|AI|封装